If you have ever purchased a pair of $300 flagship wireless earbuds, paired them with a $1,200 smartphone, and made a phone call, you have likely experienced a jarring cognitive dissonance. Your music is rendered in pristine 24-bit/96kHz lossless fidelity, yet the voice of the person you are speaking to sounds compressed, robotic, and trapped inside a tin can.
For decades, voice telephony has been the acoustic bottleneck of consumer electronics. However, a quiet paradigm shift has been occurring beneath the surface of spec sheets. Technologies marketed obliquely by companies like Samsung (in the Galaxy Buds 3 and Buds 4 series) as “Super Wideband Call Quality” or by Qualcomm as “aptX Voice” represent a fundamental teardown of legacy telecommunications standards.
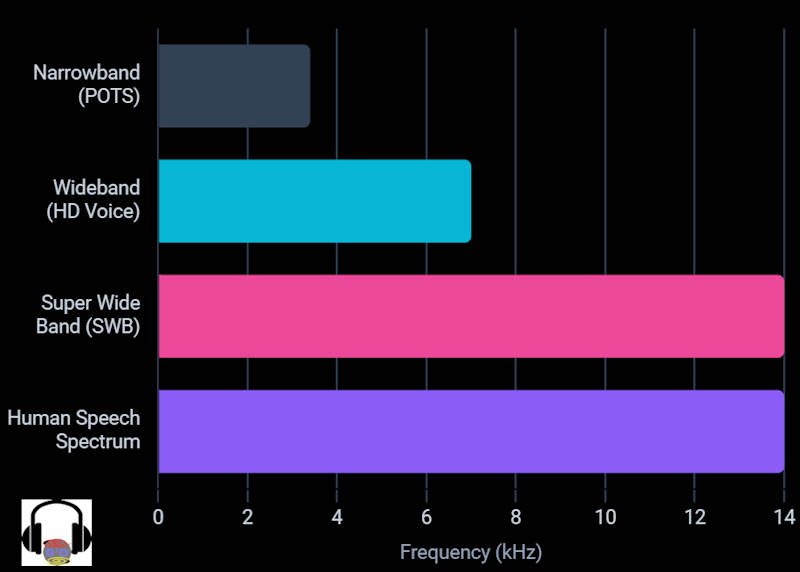
This is Super Wide Band (SWB) audio. In this definitive guide explaining Super Wide Band call quality and technology, we dissect the physical limits of human speech, the mathematics of digital sampling, and the legacy telecommunications infrastructure that has been choking our audio for over a century.
The Acoustic Physics of Human Speech
To understand why telecommunications networks historically compressed voice, and why Super Wide Band (SWB) is necessary to fix it, we must analyze the frequency spectrum of human phonation.
Human speech is not a monolithic sound; it is a complex combination of fundamental frequencies and harmonics generated by the vocal cords (voicing) and turbulent noise generated by the oral cavity (frication).
The fundamental frequency () of an adult human voice typically ranges from 85 Hz to 255 Hz. However, intelligibility—the cognitive ability to parse words—does not reside in the fundamental frequency. It resides in the formants and the high-frequency consonants.
- Vowels and Formants (300 Hz to 3 kHz): The shape of the vocal tract creates acoustic resonances called formants (). These carry the power and tonal identity of the voice.
- Fricatives and Sibilants (4 kHz to 14 kHz: Sounds like /s/, /f/, /th/, and /sh/ are produced by forcing air through narrow channels in the mouth. These sounds possess very little acoustic energy but stretch high into the frequency spectrum. The /s/ sound, for instance, has significant acoustic energy peaking between 6 kHz and 10 kHz.
If you aggressively filter out frequencies above 3.4 kHz, the human brain can no longer reliably distinguish between an /f/ and a /th/, or an /s/ and an /f/. … Read the rest


![Samsung Galaxy Buds 4 (2026) AI True Wireless Bluetooth Earbuds + $20 Gift Card, Noise Cancelling, Hi-Res Audio, 1-Way Speaker, New Fit, IP54, Live Translation, Black [US Version, 2 Yr Warranty]](https://m.media-amazon.com/images/I/31lBrdEkiML._SL160_.jpg)







![Samsung Galaxy Buds 4 Pro (2026) AI True Wireless Bluetooth Earbuds + $30 Gift Card, Hi-Res Audio, 2-Way Speaker, ANC 2.0, Optimized Comfort, IP57, Live Translation, Black [US Version, 2 Yr Warranty]](https://headphoneguidepro.com/wp-content/plugins/aawp/assets/img/placeholder-large.jpg)

![Apple Watch Series 11 [GPS 42mm] Smartwatch with Rose Gold Aluminum Case with Light Blush Sport Band - S/M. Sleep Score, Fitness Tracker, Health Monitoring, Always-On Display, Water Resistant](https://m.media-amazon.com/images/I/31J+F-pXaWL._SL160_.jpg)