If you have ever purchased a pair of $300 flagship wireless earbuds, paired them with a $1,200 smartphone, and made a phone call, you have likely experienced a jarring cognitive dissonance. Your music is rendered in pristine 24-bit/96kHz lossless fidelity, yet the voice of the person you are speaking to sounds compressed, robotic, and trapped inside a tin can.
For decades, voice telephony has been the acoustic bottleneck of consumer electronics. However, a quiet paradigm shift has been occurring beneath the surface of spec sheets. Technologies marketed obliquely by companies like Samsung (in the Galaxy Buds 3 and Buds 4 series) as “Super Wideband Call Quality” or by Qualcomm as “aptX Voice” represent a fundamental teardown of legacy telecommunications standards.
This is Super Wide Band (SWB) audio. In this definitive guide explaining Super Wide Band call quality and technology, we dissect the physical limits of human speech, the mathematics of digital sampling, and the legacy telecommunications infrastructure that has been choking our audio for over a century.
The Acoustic Physics of Human Speech
To understand why telecommunications networks historically compressed voice, and why Super Wide Band (SWB) is necessary to fix it, we must analyze the frequency spectrum of human phonation.
Human speech is not a monolithic sound; it is a complex combination of fundamental frequencies and harmonics generated by the vocal cords (voicing) and turbulent noise generated by the oral cavity (frication).
The fundamental frequency (F_0) of an adult human voice typically ranges from 85 Hz to 255 Hz. However, intelligibility—the cognitive ability to parse words—does not reside in the fundamental frequency. It resides in the formants and the high-frequency consonants.
- Vowels and Formants (300 Hz to 3 kHz): The shape of the vocal tract creates acoustic resonances called formants (F_1, F_2, F_3). These carry the power and tonal identity of the voice.
- Fricatives and Sibilants (4 kHz to 14 kHz: Sounds like /s/, /f/, /th/, and /sh/ are produced by forcing air through narrow channels in the mouth. These sounds possess very little acoustic energy but stretch high into the frequency spectrum. The /s/ sound, for instance, has significant acoustic energy peaking between 6 kHz and 10 kHz.
If you aggressively filter out frequencies above 3.4 kHz, the human brain can no longer reliably distinguish between an /f/ and a /th/, or an /s/ and an /f/. The listener is forced to rely heavily on contextual clues to decode the sentence, which dramatically increases cognitive load and leads to “listener fatigue” during long phone calls.
The Mathematics of Sampling: HD Voice vs Super Wide Band
Digital audio operates strictly according to the Nyquist-Shannon sampling theorem, which dictates that to accurately capture and reproduce a continuous analog signal, the sampling rate (f_s) must be at least twice the highest frequency present in the signal (f_{max}).
f_s \geq 2f_{max}The history of telephony is defined by how engineers manipulated this equation to save bandwidth.
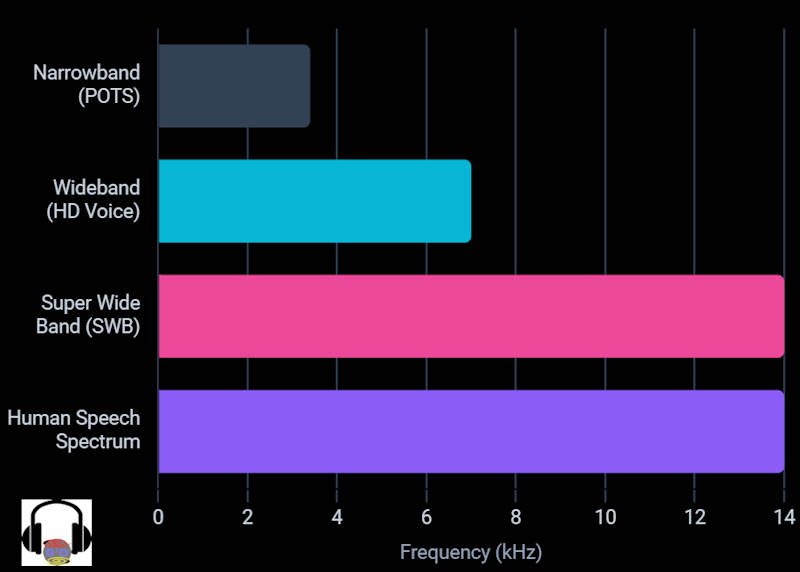
Narrowband (The POTS Era)
In the era of Plain Old Telephone Service (POTS), copper wire bandwidth was precious. Engineers determined that transmitting frequencies between 300 Hz and 3.4 kHz was the absolute minimum required for basic human intelligibility.
By applying a steep low-pass filter at 3.4 kHz, telecom networks could use a sampling rate of just 8 kHz. Using the G.711 codec with an 8-bit depth, this resulted in a strictly defined data rate:
\text{Bitrate} = 8000\text{ Hz} \times 8\text{ bits} = 64\text{ kbps}This 64 kbps stream became the foundational architecture of global telecommunications. It is why traditional phone calls sound muffled; you are literally missing the top 70% of the human vocal spectrum.
Wideband (HD Voice)
With the advent of 3G and early 4G networks, carriers introduced Wideband audio, heavily marketed as “HD Voice.” Wideband expands the frequency range from 50 Hz up to 7 kHz.
Following the Nyquist theorem, capturing 7 kHz requires a sampling rate of 16 kHz. Wideband utilizes the Adaptive Multi-Rate Wideband (AMR-WB, G.722.2) codec. By doubling the frequency ceiling, HD Voice finally captured the lower end of fricative consonants, significantly improving clarity and reducing the “muffled” quality of Narrowband.
Super Wide Band (The Modern Era)
For those wondering about HD voice vs Super Wideband, the latter is the next, and arguably final, necessary leap for human speech. SWB expands the frequency range to capture audio from 50Hz all the way to 14 kHz (and in some specifications, up to 16 kHz).
To capture 14 kHz or 16 kHz of analog sound, the ADC (Analog-to-Digital Converter) must sample the microphone array at 32 kHz (or 48 kHz, depending on the specific codec overhead). This captures virtually the entirety of the human vocal envelope, including the highest sibilants and the ambient acoustic signature of the speaker's environment, rendering the voice with startling, lifelike presence.

- THE BEST NOISE CANCELLATION: Experience powerful, adaptive noise cancelling that keeps distractions out and your music front and center. Powered by dual processors and eight adaptive microphones, the WF-1000XM6 earbuds adapt in real time to keep your world quiet and your music pure.
- CO-CREATED WITH MASTERING AUDIO ENGINEERS: Developed in collaboration with mastering audio engineers, the WF-1000XM6 earbuds deliver studio-level clarity and emotion to every track—revealing subtle details and authentic sound, all in a compact earbud.
- HD NOISE CANCELLING PROCESSOR: The HD Noise Cancelling Processor QN3e is 3x faster than the QN2e (found in our WF-1000XM5 earbuds), paired with an improved DAC and amplifier, precisely manages microphones to block out every day sounds and deliver cleaner, richer audio that feels true to the moment.
- ULTRA CLEAR CALL QUALITY: Dual beamforming microphones, a bone conduction sensor, and AI-powered noise reduction technology, isolate your voice and block background and wind noise for ultra-clear calls anywhere. Intelligent algorithms ensure every word is heard clearly—even in noisy settings.
- ERGONOMIC DESIGN AND SECURE FIT: Ergonomic earbuds contour naturally for a secure, balanced fit. Premium matte texture and smart airflow ensure all-day comfort and an elevated look, while pressure points are minimized for long listening sessions.
The Bluetooth Bottleneck of SWB: How to Improve Bluetooth Mic Quality
Even if your 5G smartphone network supports SWB via the advanced EVS (Enhanced Voice Services) codec, that high-fidelity audio must still cross the wireless gap between your phone and your earbuds. If you are researching how to improve Bluetooth mic quality, you must first understand the Bluetooth standard's historical bottleneck.
Bluetooth separates music playback and voice calls into two distinct profiles: A2DP (Advanced Audio Distribution Profile) for unidirectional high-fidelity music, and HFP (Hands-Free Profile) for bidirectional, low-latency voice communications.
Because HFP requires sending audio both ways simultaneously over a limited synchronous connection (SCO/eSCO links), it utilizes highly compressed voice codecs.
The Legacy Bluetooth Codecs
- CVSD (Continuous Variable Slope Delta modulation): The original HFP codec. It is strictly Narrowband (8 kHz sampling, 3.4 kHz audio bandwidth). If your earbuds fall back to CVSD, you are instantly transported back to 1980s landline audio quality.
- mSBC (Modified Sub-Band Coding): Introduced with the HFP 1.6 specification, mSBC brought Wideband “HD Voice” to Bluetooth headsets. It operates at a 16 kHz sampling rate, delivering up to 7 kHz of audio bandwidth. For the last decade, mSBC has been the absolute ceiling for wireless earbud call quality.
Breaking the Bottleneck: Bluetooth LE Audio and LC3
To achieve Super Wideband (SWB)over Bluetooth, the industry required a complete overhaul of the bidirectional audio architecture. This is currently achieved through three primary pathways:
- Bluetooth LE Audio LC3 Codec: Bluetooth 5.2 introduced LE (Low Energy) Audio and its mandatory codec, LC3 (Low Complexity Communications Codec). LC3 is a highly efficient, block-based transform codec utilizing the Modified Discrete Cosine Transform (MDCT). Under the LE Audio standard, LC3 can dynamically scale its sampling rate to 32 kHz for bidirectional voice, finally enabling true SWB over a standard connection.
- Qualcomm aptX Voice: In the aptX Voice vs LC3 debate, Qualcomm offers a proprietary extension of the aptX Adaptive suite within the Snapdragon Sound ecosystem. It also utilizes a 32 kHz sampling rate to deliver a 16 kHz flat frequency response for voice calls over the classic Bluetooth HFP profile, acting as a bridge until LE Audio is universally adopted.
- Proprietary Ecosystem Codecs: Companies like Samsung and Apple utilize their own proprietary transport layers over Bluetooth when connecting to their respective smartphones, bypassing standard HFP limitations entirely.
Hardware Demands: MEMS Microphones and Machine Learning
Software codecs are useless if the hardware cannot physically capture the frequencies. Super Wide Band processing places immense strain on the physical microphone arrays and the onboard Digital Signal Processors (DSPs) of wireless earbuds.
MEMS Microphone SNR Limitations
Modern earbuds utilize MEMS (Micro-Electro-Mechanical Systems) microphones. To support SWB, these capsules require an exceptionally flat frequency response extending beyond 14 kHz and a high Signal-to-Noise Ratio (SNR).
Standard earbud microphones typically feature an SNR of around 60 dB to 64 dB. The electrical self-noise (the “hiss” generated by the microphone's own circuitry) effectively masks high-frequency micro-details. To achieve true SWB clarity, manufacturers must source premium components; tracking the MEMS microphone SNR reveals that true flagship earbuds require sensors pushing 70 dB or higher.
The DSP and Noise Suppression Paradox
The greatest challenge in engineering SWB earbuds is algorithmic noise suppression.
In a traditional Narrowband system, the DSP can simply apply a brutal low-pass filter at 3.4 kHz to chop off any high-frequency wind noise, tire screeching, or mechanical hums. With Super Wideband, you cannot do this. If the DSP chops off high frequencies to eliminate wind noise, it simultaneously destroys the high-frequency sibilants 8 kHz to 14 kHz) of the user's voice.
To solve this, flagship earbuds rely on Machine Learning (ML) acoustic models. The onboard NPU runs real-time inferencing to separate the spectral footprint of a human voice from the spectral footprint of background noise, even when they occupy the exact same high-frequency bands.
Voice Pickup Units (VPUs)
To aid the ML models, premium earbuds integrate bone conduction sensors (VPUs). These measure the physical vibration of the jawbone when the user speaks. Because environmental noise cannot vibrate the jawbone, the VPU acts as a flawless acoustic gate.
The Tangible Advantages of Super Wide Band
The shift from Wideband (7 kHz) to Super Wideband (14 kHz+) is not merely a specification bump; it has profound, measurable impacts on human communication.
- Reduction of Cognitive Load: When high-frequency fricatives are missing, the brain must actively predict missing phonemes based on context. SWB consistently scores significantly higher in intelligibility algorithms like POLQA, directly translating to less mental fatigue during long conference calls.
- Spatial and Environmental Presence: SWB captures the subtle acoustic reflections of the room. Instead of sounding like a disembodied, compressed voice, the speaker sounds physically present in an acoustic space.
- Speaker Identification and Nuance: Emotion, sarcasm, and subtle vocal inflections are largely carried in high-frequency harmonics, allowing for immediate speaker identification in multi-person conference calls.
The Flagship Landscape: How the Giants Implement SWB
Because the Bluetooth standard is highly fragmented, the implementation of Super Wide Band voice depends entirely on the ecosystem you buy into.
Samsung (Galaxy Buds 3, Buds 3 Pro, and Buds 4 Series)
Samsung has been one of the most aggressive proponents of this tech, heavily marketing Samsung Super Wideband call quality.
When paired with a modern Galaxy smartphone, the Galaxy Buds 4 Pro bypass standard Bluetooth HFP protocols. They utilize a massive ML model trained on diverse noise environments, sampling the microphone array at 32 kHz. If the data link degrades, the S-series smartphone's NPU utilizes an AI restoration algorithm to synthetically rebuild the missing high-frequency harmonics before transmitting it over the carrier's EVS-enabled VoLTE network.
![Samsung Galaxy Buds 4 (2026) AI True Wireless Bluetooth Earbuds + $20 Gift Card, Noise Cancelling, Hi-Res Audio, 1-Way Speaker, New Fit, IP54, Live Translation, Black [US Version, 2 Yr Warranty]](https://m.media-amazon.com/images/I/31lBrdEkiML._SL160_.jpg)

Apple (AirPods Pro 2, AirPods 4, AirPods Pro 3)
Apple rarely uses industry-standard terminology, but achieves SWB primarily through its AAC-ELD (Advanced Audio Coding – Enhanced Low Delay) codec. AAC-ELD is a brilliant piece of engineering that operates at a 24 kHz or even 48 kHz sampling rate with sub-15 ms algorithmic delay. When making a FaceTime Audio call using AirPods Pro connected to an iPhone, the audio stream utilizes AAC-ELD, delivering pristine bandwidth.
![Apple Watch Series 11 [GPS 42mm] Smartwatch with Rose Gold Aluminum Case with Light Blush Sport Band - S/M. Sleep Score, Fitness Tracker, Health Monitoring, Always-On Display, Water Resistant](https://m.media-amazon.com/images/I/31J+F-pXaWL._SL160_.jpg)

Sony (WF-1000XM5, WF-1000XM6, WH-1000XM5, and WH-1000XM6)
For SWB transmission, Sony relies on the adoption of LE Audio. If paired to a device that supports modern Bluetooth LE Audio profiles, the earbuds utilize the LC3 codec to scale up to a 32 kHz sampling rate for SWB calls. If LE Audio is not supported, they fall back to the standard 16 kHz mSBC Wideband profile, relying on their aggressive DNN algorithms to clean up the sound.
Bose and Qualcomm (QuietComfort Ultra and aptX Ecosystem)
Bose largely relies on Qualcomm’s silicon. The QuietComfort Ultra earbuds are integrated into the Snapdragon Sound ecosystem, granting them access to aptX Voice. It utilizes a 32kHz sampled audio profile over the Bluetooth HFP link. This provides a plug-and-play SWB experience for compatible Android users; iPhone users, unfortunately, are locked out entirely.

Conclusion: The Silent Revolution
Super Wide Band voice technology is arguably the most important acoustic advancement since the transition from analog to digital cellular networks. By escaping the century-old 3.4 kHz limitation of traditional telephony and the archaic 7 kHz bottleneck of legacy Bluetooth profiles, SWB finally allows human voices to sound human.
This article is part of our Headphone 101 series, dedicated to demystifying the complex engineering behind modern acoustic technology. Explore our other technical deep-dives to master the hardware that drives your daily audio experience.
You may check Headphone 101 for detailed explanations of headphone technologies and terms.
For Bluetooth headphone guides, please check the Bluetooth headphones section.
The sports headphones section is dedicated to guides on sports headphones.
You may also reach us through our Facebook page.

Leave a Reply